Introduction: Keynes, Friedman, Modigliani¶

# Some initial setup
from HARK.ConsumptionSaving.ConsIndShockModel import PerfForesightConsumerType
import pandas_datareader.data as web
import statsmodels.formula.api as sm
import scipy.stats as stats
import datetime as dt
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
plt.style.use("seaborn-v0_8-darkgrid")
palette = plt.get_cmap("Dark2")
pd.core.common.is_list_like = pd.api.types.is_list_like1. The Keynesian consumption function¶
Keynes:
“The amount of aggregate consumption mainly depends on the amount of aggregate income.”
It is a “fundamental psychological rule ... that when ... real income increases ... consumption [will increase], but by less than the increase in income.”
More generally, “as a rule, a greater proportion of income ... is saved as real income increases.”
This can be formalized as:
$
$
for
The Keynesian Consumption Function¶
class KeynesianConsumer:
"""
This class represents consumers that behave according to a
Keynesian consumption function, representing them as a
special case of HARK's PerfForesightConsumerType
Methods:
- cFunc: computes consumption/permanent income
given total income/permanent income.
"""
def __init__(self):
Keynesian = (
PerfForesightConsumerType()
) # set up a consumer type and use default parameteres
Keynesian.cycles = 0 # Make this type have an infinite horizon
Keynesian.DiscFac = 0.05
Keynesian.PermGroFac = [0.7]
Keynesian.solve() # solve the consumer's problem
Keynesian.unpack("cFunc") # unpack the consumption function
self.cFunc = Keynesian.solution[0].cFunc
self.a0 = self.cFunc(0)
self.a1 = self.cFunc(1) - self.cFunc(0)# Plot cFunc(Y)=Y against the Keynesian consumption function
# Deaton-Friedman consumption function is a special case of perfect foresight model
# We first create a Keynesian consumer
KeynesianExample = KeynesianConsumer()
# and then plot its consumption function
income = np.linspace(0, 30, 20) # pick some income points
plt.figure(figsize=(9, 6))
plt.plot(
income, KeynesianExample.cFunc(income), label="Consumption function"
) # plot income versus the consumption
plt.plot(income, income, "k--", label="C=Y")
plt.title("Consumption function")
plt.xlabel("Income (y)")
plt.ylabel("Normalized Consumption (c)")
plt.ylim(0, 20)
plt.legend()
plt.show()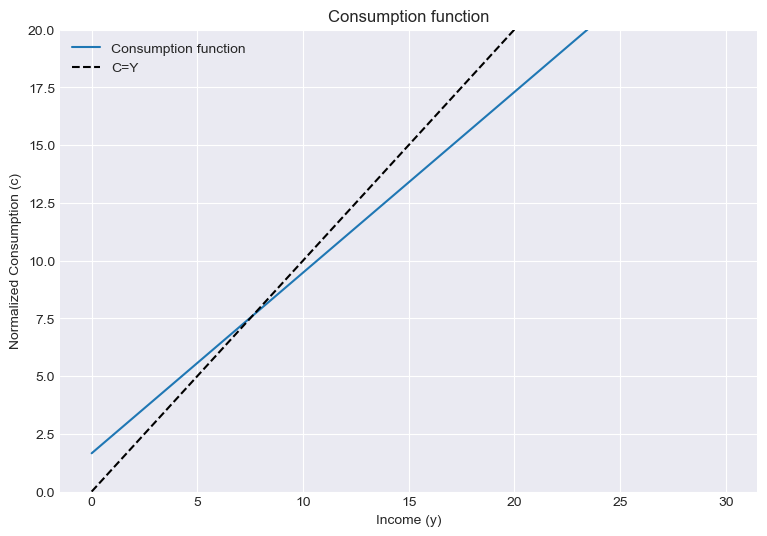
# This looks like the first of the three equations, consumption as a linear function of income!
# This means that even in a microfounded model (that HARK provides), the consumption function can match Keynes reduced form
# prediction (given the right parameterization).
# We can even find a_0 and a_1
a_0 = KeynesianExample.a0
a_1 = KeynesianExample.a1
print("a_0 is {:.2f}".format(a_0))
print("a_1 is {:.2f}".format(a_1))a_0 is 1.66
a_1 is 0.78
The Keynesian consumption function: Evidence¶
Aggregate Data:
Long-term time-series estimates: close to zero, close to 1 (saving rate stable over time - Kuznets).
Short-term aggregate time-series estimates of change in consumption on change in income find .
finds significant , near 1.
# Lets have a look at some aggregate data
sdt = dt.datetime(1990, 1, 1) # set startdate
edt = dt.datetime(2020, 1, 1) # set end date
df = web.DataReader(
["PCECC96", "DPIC96"], "fred", sdt, edt
) # import the data from Fred
# Plot the data
plt.figure(figsize=(9, 6))
plt.plot(df.DPIC96, df.PCECC96, "go", markersize=3.0, label="Data")
slope, intercept, r_value, p_value, std_err = stats.linregress(df.DPIC96, df.PCECC96)
plt.plot(df.DPIC96, intercept + slope * df.DPIC96, "k-", label="Line of best fit")
plt.plot(df.DPIC96, df.DPIC96, "k--", label="C=Y")
plt.xlabel("Income (y)")
plt.ylabel("Consumption (c)")
plt.legend()
plt.show()
print("a_0 is {:.2f}".format(intercept))
print("a_1 is {:.2f}".format(slope))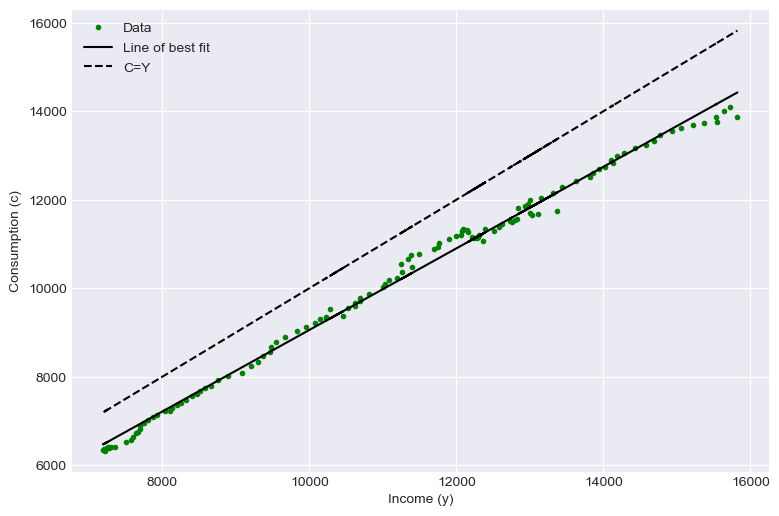
a_0 is -161.03
a_1 is 0.92
# However, our consumption data is [non-stationary](https://www.reed.edu/economics/parker/312/tschapters/S13_Ch_4.pdf) and this drives the previous
# estimate.
df.DPIC96.plot()
plt.xlabel("Date")
plt.ylabel("Consumption (c)")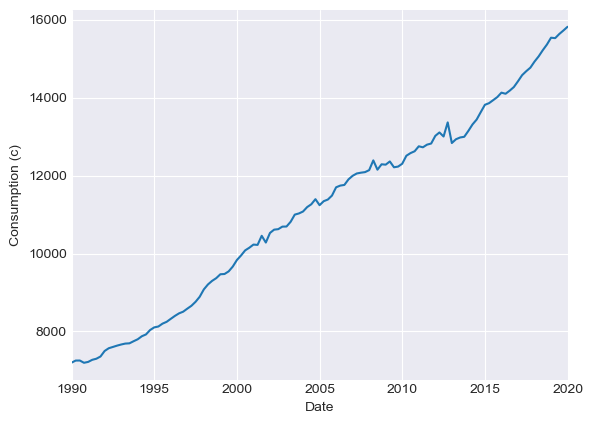
# Lets use our second equation to try to find an estimate of a_1
df_diff = df.diff() # create dataframe of differenced values
# Plot the data
plt.figure(figsize=(9, 6))
plt.plot(df_diff.DPIC96, df_diff.PCECC96, "go", markersize=3.0, label="Data")
slope, intercept, r_value, p_value, std_err = stats.linregress(
df_diff.DPIC96[1:], df_diff.PCECC96[1:]
) # find line of best fit
plt.plot(
df_diff.DPIC96[1:],
intercept + slope * df_diff.DPIC96[1:],
"k-",
label="Line of best fit",
)
plt.plot(np.array([-200, 200]), np.array([-200, 200]), "k--", label="C=Y")
plt.xlabel("Change in income (dy)")
plt.ylabel("Change in consumption (dc)")
plt.legend()
plt.show()
print("a_1 is {:.2f}".format(slope))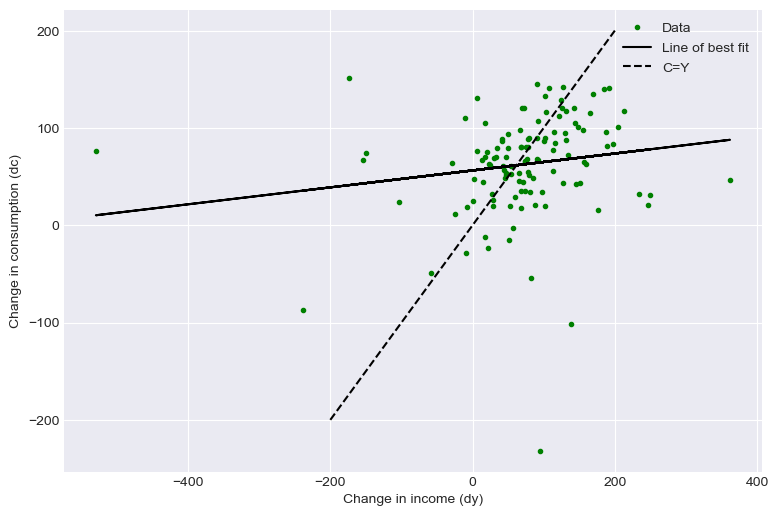
a_1 is 0.09
a_1 is now much lower, as we expected
Household Data:¶
Cross-section plots of consumption and income: very large and significant , maybe 0.5.
Further facts:
Black households save more than whites at a given income level.
By income group:
low-income: Implausibly large dissaving (spend 2 or 3 times income)
high-income: Remarkably high saving
2. Duesenberry¶
Habit formation may explain why affects .
Relative Income Hypothesis suggests that you compare your consumption to consumption of ‘peers’.
May explain high saving rates of Black HHs.
Problems with Duesenberry:
No budget constraint
No serious treatment of intertemporal nature of saving
Dusenberry: Evidence¶
# Even if we control for income, past consumption seems to be significantly related to current consumption
df_habit = df.copy()
df_habit.columns = ["cons", "inc"]
df_habit["cons_m1"] = df.PCECC96.shift()
df_habit.dropna()
result = sm.ols(formula="cons ~ inc + cons_m1", data=df_habit.dropna()).fit()
result.summary()# The coefficient on lagged consumption is very significant.
# But regression may be statistically problematic for the usual [non-stationarity](https://towardsdatascience.com/stationarity-in-time-series-analysis-90c94f27322) reasons.3. Friedman’s Permanent Income Hypothesis¶
We can try to test this theory across households. If we run a regression of the form:
And if Friedman is correct, and the “true” coefficient on permanent income is 1, then the coefficient on will be:
Friedman’s Permanent Income Hypothesis¶
We begin by creating a class that class implements the Friedman PIH consumption function as a special case of the Perfect Foresight CRRA model.
As discussed in the lecture notes, it is often convenient to represent this type of models in variables that are normalized by permanent income. That is the case for the HARK tools that we use below in the definition of our consumer. Therefore, the consumption function will expect
and compute
Therefore, to find consumption at a total level of income , we will use .
class FriedmanPIHConsumer:
"""
This class represents consumers that behave according to
Friedman's permanent income hypothesis, representing them as a
special case of HARK's PerfForesightConsumerType
Methods:
- cFunc: computes consumption/permanent income
given total income/permanent income.
"""
def __init__(self, Rfree=1.001, CRRA=2):
FriedmanPIH = (
PerfForesightConsumerType()
) # set up a consumer type and use default parameteres
FriedmanPIH.cycles = 0 # Make this type have an infinite horizon
FriedmanPIH.DiscFac = 1 / Rfree
FriedmanPIH.Rfree = [Rfree]
FriedmanPIH.LivPrb = [1.0]
FriedmanPIH.PermGroFac = [1.0]
FriedmanPIH.CRRA = CRRA
FriedmanPIH.solve() # solve the consumer's problem
FriedmanPIH.unpack("cFunc") # unpack the consumption function
self.cFunc = FriedmanPIH.solution[0].cFuncNow, think of a consumer that has a permanent income of 1. What will be his consumption at different levels of total observed income?
# We can now create a PIH consumer
PIHexample = FriedmanPIHConsumer()
# Plot the perfect foresight consumption function
income = np.linspace(0, 10, 20) # pick some income points
plt.figure(figsize=(9, 6))
plt.plot(
income, PIHexample.cFunc(income), label="Consumption function"
) # plot income versus the consumption
plt.plot(income, income, "k--", label="C=Y")
plt.title("Consumption function")
plt.xlabel("Normalized Income (y)")
plt.ylabel("Normalized Consumption (c)")
plt.legend()
plt.show()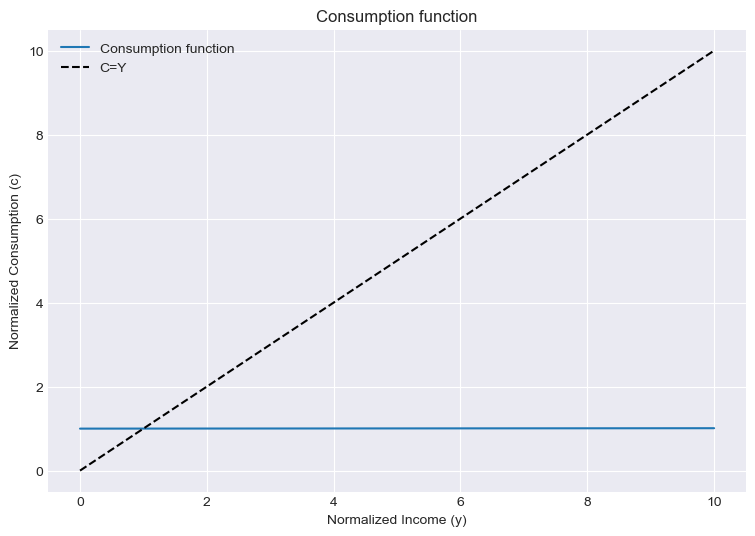
We can see that regardless of the income our agent receives, they consume their permanent income, which is normalized to 1.
We can also draw out some implications of the PIH that we can then test with evidence
If we look at HH’s who have very similar permanent incomes, we should get a small estimate of , because is large relative to .
Lets simulate this using our consumer.
# Permanent income has the same variance
# as transitory income.
perm_inc = np.random.normal(1.0, 0.1, 200)
trans_inc = np.random.normal(0.5, 0.1, 200)
total_inc = perm_inc + trans_inc
slope, intercept, r_value, p_value, std_err = stats.linregress(
total_inc, PIHexample.cFunc(total_inc / perm_inc) * perm_inc
)
plt.figure(figsize=(9, 6))
plt.plot(
total_inc, PIHexample.cFunc(total_inc) * perm_inc, "go", label="Simulated data"
)
plt.plot(total_inc, intercept + slope * total_inc, "k-", label="Line of best fit")
plt.plot(np.linspace(1, 2, 5), np.linspace(1, 2, 5), "k--", label="C=Y")
plt.xlabel("Income (y)")
plt.ylabel("Consumption (c)")
plt.legend()
plt.ylim(0, 2)
plt.xlim(1.1, 1.9)
plt.show()
print("a_0 is {:.2f}".format(intercept))
print("a_1 is {:.2f}".format(slope))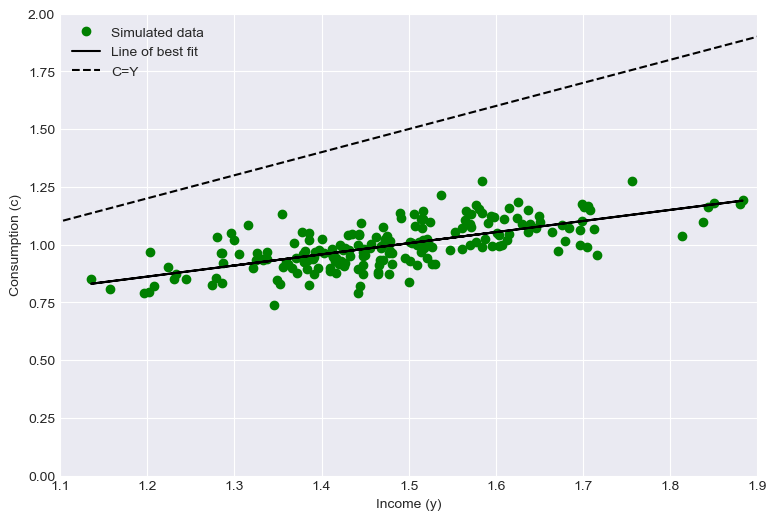
a_0 is 0.28
a_1 is 0.48
# Permanent income with higher variance
perm_inc = np.random.normal(1.0, 0.5, 200)
trans_inc = np.random.normal(0.5, 0.1, 200)
total_inc = perm_inc + trans_inc
slope, intercept, r_value, p_value, std_err = stats.linregress(
total_inc, PIHexample.cFunc(total_inc / perm_inc) * perm_inc
)
plt.figure(figsize=(9, 6))
plt.plot(
total_inc, PIHexample.cFunc(total_inc) * perm_inc, "go", label="Simulated data"
)
plt.plot(total_inc, intercept + slope * total_inc, "k-", label="Line of best fit")
plt.plot(np.linspace(0, 2, 5), np.linspace(0, 2, 5), "k--", label="C=Y")
plt.xlabel("Income (y)")
plt.ylabel("Consumption (c)")
plt.legend()
plt.ylim(0, 2)
plt.show()
print("a_0 is {:.2f}".format(intercept))
print("a_1 is {:.2f}".format(slope))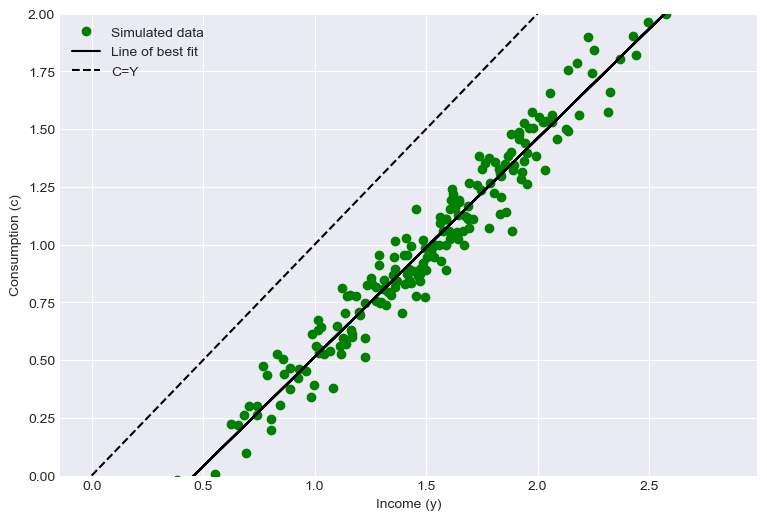
a_0 is -0.43
a_1 is 0.95
We can see that as we increase the variance of permanent income, the estimate of a_1 rises
Friedman’s Permanent Income Hypothesis: Evidence¶
We can now consider the empirical evidence for the claims our model made about the PIH.
If we take a long time series, then the differences in permanent income should be the main driver of the variance in total income. This implies that a_1 should be high.
If we take higher frequency time series (or cross sectional data), transitory shocks should dominate, and our estimate of a_1 should be lower.
Consider quarterly differences first:
# Lets use the data from FRED that we used before.
# Using quarterly data (copying from above), we had:
plt.figure(figsize=(9, 6))
plt.plot(df_diff.DPIC96, df_diff.PCECC96, "go", markersize=3.0, label="Data")
slope, intercept, r_value, p_value, std_err = stats.linregress(
df_diff.DPIC96[1:], df_diff.PCECC96[1:]
) # find line of best fit
plt.plot(
df_diff.DPIC96[1:],
intercept + slope * df_diff.DPIC96[1:],
"k-",
label="Line of best fit",
)
plt.plot(np.array([-200, 200]), np.array([-200, 200]), "k--", label="C=Y")
plt.xlabel("Change in income (dy)")
plt.ylabel("Change in consumption (dc)")
plt.legend()
plt.show()
print("a_1 is {:.2f}".format(slope))a_1 is 0.09
And now consider longer time differences, 20 quarters for instance, where the changes in permanent income should dominate transitory effects
# Using longer differences
df_diff_long = df.diff(periods=20) # create dataframe of differenced values
df_diff_long.columns = ["cons", "inc"]
plt.figure(figsize=(9, 6))
plt.plot(df_diff_long.inc, df_diff_long.cons, "go", label="Data")
slope, intercept, r_value, p_value, std_err = stats.linregress(
df_diff_long.inc[20:], df_diff_long.cons[20:]
) # find line of best fit
plt.plot(
df_diff_long.inc[1:],
intercept + slope * df_diff_long.inc[1:],
"k-",
label="Line of best fit",
)
plt.plot(np.linspace(-100, 2000, 3), np.linspace(-100, 2000, 3), "k--", label="C=Y")
plt.legend()
plt.xlabel("Change in income (dy)")
plt.ylabel("Change in consumption (dc)")
plt.show()
print("a_0 is {:.2f}".format(intercept))
print("a_1 is {:.2f}".format(slope))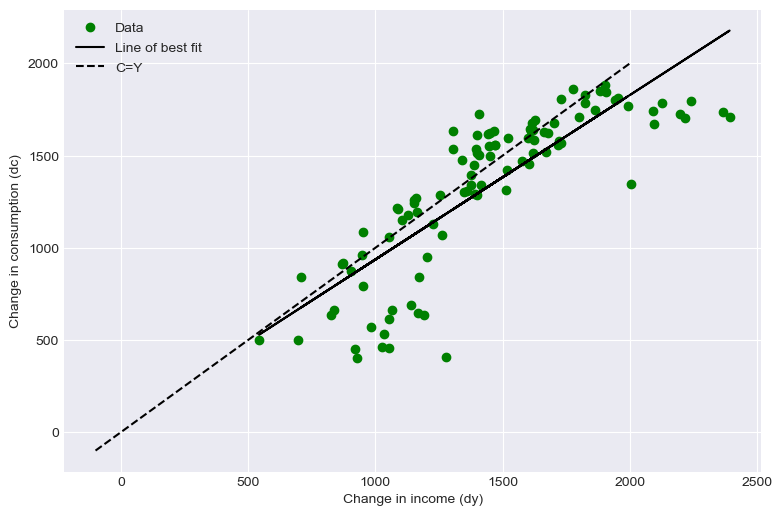
a_0 is 44.88
a_1 is 0.89
The estimate of using the longer differences is much higher because permanent income is playing a much more important role in explaining the variation in consumption.