A Demonstration of the Harmenberg (2021) Aggregation Method¶
Authors: Christopher D. Carroll, Mateo Velásquez-Giraldo¶
# Set Up the Computational Environment: (in JupyterLab, click the dots)
# Preliminaries
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from copy import deepcopy
from HARK.distributions import calc_expectation
from HARK.ConsumptionSaving.ConsIndShockModel import (
IndShockConsumerType,
init_idiosyncratic_shocks,
)Description of the problem¶
\newcommand{\def}{:=}
Macroeconomic models with heterogeneous agents sometimes incorporate a microeconomic income process with a permanent component (\pLvl_t) that follows a geometric random walk. To find an aggregate characteristic of these economies such as aggregate consumption \CLvl_t, one must integrate over permanent income (and all the other relevant state variables):
Undefined control sequence: \CLvl at position 1: \̲C̲L̲v̲l̲_t = \int_{\pLv…
\CLvl_t = \int_{\pLvl} \int_{\mLvl} \mathrm{c}(\mLvl,\pLvl) \times f_t(\mLvl,\pLvl) \, d \mLvl\, d\pLvl,where \mLvl denotes any other state variables that consumption might depend on, \cFunc(\cdot,\cdot) is the individual consumption function, and is the joint density function of permanent income and the other state variables at time .
Under the usual assumption of Constant Relative Risk Aversion utility and standard assumptions about the budget constraint, such models are homothetic. This means that for a state variable \mLvl one can solve for a normalized policy function \cFunc(\cdot) such that
Undefined control sequence: \mLvl at position 12: \mathrm{c}(\̲m̲L̲v̲l̲,\pLvl) = \math…
\mathrm{c}(\mLvl,\pLvl) = \mathrm{c}\left(\mLvl/\pLvl\right)\times \pLvlIn practice, this implies that one can defined a normalized state vector \mNrm = \mLvl/\pLvl and solve for the normalized policy function. This eliminates one dimension of the optimization problem problem, \pLvl.
While convenient for the solution of the agents’ optimization problem, homotheticity has not simplified our aggregation calculations as we still have
Undefined control sequence: \CLvl at position 15: \begin{split}
\̲C̲L̲v̲l̲_t =& \int \int…
\begin{split}
\CLvl_t =& \int \int \cFunc(\mLvl,\pLvl) \times f_t(\mLvl,\pLvl) \, d\mLvl\, d\pLvl\\
=& \int \int \cFunc\left(\frac{1}{\pLvl}\times \mLvl\right)\times \pLvl \times f_t(\mLvl,\pLvl) \, d\mLvl\, d\pLvl,
\end{split}which depends on \pLvl.
To further complicate matters, we usually do not have analytical expressions for \cFunc(\cdot) or f_t(\mLvl,\pLvl). What we often do in practice is to simulate a population of agents for a large number of periods using the model’s policy functions and transition equations. The result is a set of observations \{\mLvl_{i,t},\pLvl_{i,t}\}_{i\in I, 0\leq t\leq T} which we then use to approximate
Undefined control sequence: \CLvl at position 1: \̲C̲L̲v̲l̲_t \approx \fra…
\CLvl_t \approx \frac{1}{|I|}\sum_{i \in I} \cFunc\left(\mLvl_{i,t}/\pLvl_{i,t}\right)\times \pLvl_{i,t}.At least two features of the previous strategy are unpleasant:
We have to simulate the distribution of permanent income, even though the model’s solution does not depend on it.
As a geometric random walk, permanent income might have an unbounded distribution. Since \pLvl_{i,t} appears multiplicatively in our approximation, agents with high permanent incomes will be the most important in determining levels of aggregate variables. Therefore, it is important for our simulated population to achieve a good approximation of the distribution of permanent income among the small number of agents with very high permanent income, which will require us to use many agents (large , requiring considerable computational resources).
Harmenberg (2021) solves both problems. His solution constructs a distribution of the normalized state vector that he calls the permanent-income-weighted distribution and which has the convenient property that
Undefined control sequence: \CLvl at position 15: \begin{split}
\̲C̲L̲v̲l̲_t =& \int \int…
\begin{split}
\CLvl_t =& \int \int \cFunc\left(\frac{1}{\pLvl}\times \mLvl\right)\times \pLvl \times f_t(\mLvl,\pLvl) \, d\mLvl\, d\pLvl\\
=& \int \cFunc\left(\mNrm\right) \times \tilde{f}(\mNrm) \, d\mNrm.
\end{split}Therefore, his solution allows us to calculate aggregate variables without the need to keep track of the distribution of permanent income. Additionally, the method eliminates the issue of a small number of agents in the tail having an outsized influence in our approximation and this makes it much more precise.
This notebook briefly describes Harmenberg’s method and demonstrates its implementation in the HARK toolkit.
Description of the method¶
To illustrate Harmenberg’s idea, consider a buffer stock saving model in which:
The individual agent’s problem has two state variables:
Market resources \mLvl_{i,t}.
Permanent income \pLvl_{i,t}.
The agent’s problem is homothetic in permanent income, so that we can define m_t = \mLvl_t/\pLvl_t and find a normalized policy function \cFunc(\cdot) such that
Undefined control sequence: \cFunc at position 1: \̲c̲F̲u̲n̲c̲(\mNrm) \times …
\cFunc(\mNrm) \times \pLvl_t = \cFunc(\mLvl_t, \pLvl_t) \,\,\qquad \forall(\mLvl_t, \pLvl_t)where \cFunc(\cdot,\cdot) is the optimal consumption function.
\pLvl_t evolves according to
Undefined control sequence: \pLvl at position 1: \̲p̲L̲v̲l̲_{t+1} = \PermG… \pLvl_{t+1} = \PermGroFac \PermShk_{t+1} \pLvl_t,where \PermShk_{t+1} is a shock with density function f_{\PermShk}(\cdot) satisfying \Ex_t[\PermShk_{t+1}] = 1.
To compute aggregate consumption \CLvl_t in this model, we would follow the approach from above
Undefined control sequence: \CLvl at position 1: \̲C̲L̲v̲l̲_t = \int \int …
\CLvl_t = \int \int \cFunc(\mNrm)\times\pLvl \times \mpLvlDstn_t(\mNrm,\pLvl) \, d\mNrm \, d\pLvl,where \mpLvlDstn_t(\mNrm,\pLvl) is the measure of agents with normalized resources \mNrm and permanent income \pLvl.
First insight¶
The first of Harmenberg’s insights is that the previous integral can be rearranged as
Undefined control sequence: \CLvl at position 1: \̲C̲L̲v̲l̲_t = \int_{\mNr…
\CLvl_t = \int_{\mNrm} \cFunc(\mNrm)\left(\int \pLvl \times \mpLvlDstn_t(\mNrm,\pLvl) \, d\pLvl\right) \, d\mNrm.The inner integral, \int_{\pLvl} \pLvl \times \mpLvlDstn_t(\mNrm,\pLvl) \, d\pLvl, is a function of \mNrm and it measures the total amount of permanent income accruing to agents with normalized market resources of \mNrm. De-trending this object by the deterministic component of growth in permanent income \PermGroFac, Harmenberg defines the permanent-income-weighted distribution \mWgtDstnMarg(\cdot) as
Undefined control sequence: \mWgtDstnMarg at position 1: \̲m̲W̲g̲t̲D̲s̲t̲n̲M̲a̲r̲g̲_{t}(\mNrm) \de…
\mWgtDstnMarg_{t}(\mNrm) \def \PermGroFac^{-t}\int_{\pLvl} \pLvl \times \mpLvlDstn_t(\mNrm,\pLvl) \, d\pLvl.The definition allows us to rewrite
Undefined control sequence: \CLvl at position 1: \̲C̲L̲v̲l̲_{t} = \PermGro…
\CLvl_{t} = \PermGroFac^t \int_{m} \cFunc(\mNrm) \times \mWgtDstnMarg_t(\mNrm) \, dm.There are no computational advances yet: We have merely hidden the joint distribution of (\mNrm,\pLvl) inside the \mWgtDstnMarg object we have defined. This helps us notice that \mWgtDstnMarg is the only object besides the solution that we need in order to compute aggregate consumption. But we still have no practial way of computing or approximating \mWgtDstnMarg.
Second insight¶
Harmenberg’s second insight produces a simple way of generating simulated counterparts of \mWgtDstnMarg without having to simulate permanent incomes.
We start with the density function of \mNrm_{t+1} given \mNrm_t and \PermShk_{t+1}, \kernel(\mNrm_{t+1}|\mNrm_t,\PermShk_{t+1}). This density will depend on the model’s transition equations and draws of random variables like transitory shocks to income in or random returns to savings between and . If we can simulate those things, then we can sample from \kernel(\cdot|\mNrm_t,\PermShk_{t+1}).
Harmenberg shows that
Undefined control sequence: \mWgtDstnMarg at position 25: …ransition: }\̲m̲W̲g̲t̲D̲s̲t̲n̲M̲a̲r̲g̲_{t+1}(\mNrm_{t…
\texttt{transition: }\mWgtDstnMarg_{t+1}(\mNrm_{t+1}) = \int \kernel(\mNrm_{t+1}|\mNrm_t, \PermShk_t) \pShkNeutDstn(\PermShk_{t+1}) \mWgtDstnMarg_t(\mNrm_t)\, d\mNrm_t\, d\PermShk_{t+1},where \pShkNeutDstn is an altered density function for the permanent income shocks \PermShk, which he calls the permanent-income-neutral measure, and which relates to the original density f_{\PermShk} through
Undefined control sequence: \pShkNeutDstn at position 1: \̲p̲S̲h̲k̲N̲e̲u̲t̲D̲s̲t̲n̲(\PermShk_{t+1}…
\pShkNeutDstn(\PermShk_{t+1})\def \PermShk_{t+1}f_{\PermShk}(\PermShk_{t+1})\,\,\, \forall \PermShk_{t+1}.What’s remarkable about this equation is that it gives us a way to obtain a distribution \mWgtDstnMarg_{t+1} from \mWgtDstnMarg_t:
Start with a population whose \mNrm is distributed according to \mWgtDstnMarg_t.
Give that population permanent income shocks with distribution \pShkNeutDstn.
Apply the transition equations and other shocks of the model to obtain \mNrm_{t+1} from \mNrm_{t} and \PermShk_{t+1} for every agent.
The distribution of \mNrm across the resulting population will be \mWgtDstnMarg_{t+1}.
Notice that the only change in these steps from what how we would usually simulate the model is that we now draw permanent income shocks from \pShkNeutDstn instead of f_{\PermShk}. Therefore, with this procedure we can approximate \mWgtDstnMarg_t and compute aggregates using formulas like the equation transition, all without tracking permanent income and with few changes to the code we use to simulate the model.
Harmenberg’s method in HARK¶
Harmenberg’s method for simulating under the permanent-income-neutral measure is available in HARK’s IndShockConsumerType class and the (many) models that inherit its income process, such as PortfolioConsumerType.
As the cell below illustrates, using Harmenberg’s method in HARK simply requires setting an agent’s property agent.neutral_measure = True and then computing the discrete approximation to the income process. After these steps, agent.simulate will simulate the model using Harmenberg’s permanent-income-neutral measure.
# Implementation in HARK:
Farther down in the notebook, code like this solves the standard model:¶
# Create a population with the default parametrization
popn = IndShockConsumerType(**params)
# Specify which variables to track in the simulation
popn.track_vars=[
'mNrm', # mLvl normalized by permanent income (mLvl = market resources)
'cNrm', # cLvl normalized by permanent income (cLvl = consumption)
'pLvl'] # pLvl: permanent income
popn.cycles = 0 # No life cycles -- an infinite horizon
# Solve for the consumption function
popn.solve()
# Simulate under the base measure
popn.initialize_sim()
popn.simulate()Later, code like this simulates using the permanent-income-neutral measure¶
# Harmenberg permanent-income-neutral simulation
# Make a clone of the population weighted solution
ntrl = deepcopy(popn)
# Change the income process to use the neutral measure
ntrl.neutral_measure = True
ntrl.update_income_process()
# Simulate
ntrl.initialize_sim()
ntrl.simulate()All we had to do differently to simulate using the permanent-income-neutral measure was to set the agent’s property neutral_measure=True.
This is implemented when the function update_income_process re-constructs the agent’s income process. The specific lines that achieve the change of measure in HARK are in this link, or reproduced here:
if self.neutral_measure == True:
PermShkDstn_t.pmv = PermShkDstn_t.atoms*PermShkDstn_t.pmvSimple!
The efficiency gain from using Harmenberg’s method¶
To demonstrate the gain in efficiency from using Harmenberg’s method, we will set up the following experiment.
Consider an economy populated by Buffer-Stock savers, whose individual-level state variables are market resources \mLvl_t and permanent income \pLvl_t. Such agents have a homothetic consumption function, so that we can define normalized market resources \mNrm_t \def \mLvl_t / \pLvl_t, solve for a normalized consumption function \cFunc(\cdot), and express the consumption function as \cFunc(\mLvl,\pLvl) = \cFunc(\mNrm)\times\pLvl.
Assume further that mortality, impatience, and permanent income growth are such that the economy converges to stable joint distribution of \mNrm and \pLvl characterized by the density function . Under these conditions, define the stable level of aggregate market resources and consumption as
Undefined control sequence: \MLvl at position 1: \̲M̲L̲v̲l̲ ̲\def \int \int …
\MLvl \def \int \int \mNrm \times \pLvl \times f(\mNrm, \pLvl)\,d\mNrm \,d\pLvl, \,\,\, \CLvl \def \int \int \cFunc(\mNrm) \times \pLvl \times f(\mNrm, \pLvl)\,d\mNrm \,d\pLvl.If we could simulate the economy with a continuum of agents we would find that, over time, our estimate of aggregate market resources \MLvlest_t would converge to \MLvl and \CLvlest_t would converge to \CLvl. Therefore, if we computed our aggregate estimates at different periods in time we would find them to be close:
Undefined control sequence: \MLvlest at position 1: \̲M̲L̲v̲l̲e̲s̲t̲_t \approx \MLv…
\MLvlest_t \approx \MLvlest_{t+n} \approx \MLvl \,\,
\text{and} \,\,
\CLvlest_t \approx \CLvlest_{t+n} \approx \CLvl, \,\,
\text{for } n>0 \text{ and } t \text{ large enough}.In practice, however, we rely on approximations using a finite number of agents . Our estimates of aggregate market resources and consumption at time are
Undefined control sequence: \MLvlest at position 1: \̲M̲L̲v̲l̲e̲s̲t̲_t \def \frac{1…
\MLvlest_t \def \frac{1}{I} \sum_{i=1}^{I} m_{i,t}\times\pLvl_{i,t}, \,\,\, \CLvlest_t \def \frac{1}{I} \sum_{i=1}^{I} \cFunc(m_{i,t})\times\pLvl_{i,t},under the basic simulation strategy or
Undefined control sequence: \MLvlest at position 1: \̲M̲L̲v̲l̲e̲s̲t̲_t \def \frac{1…
\MLvlest_t \def \frac{1}{I} \sum_{i=1}^{I} \tilde{m}_{i,t}, \,\,\, \CLvlest_t \def \frac{1}{I} \sum_{i=1}^{I} \cFunc(\tilde{m}_{i,t}),if we use Harmenberg’s method to simulate the distribution of normalized market resources under the permanent-income neutral measure.
If we do not use enough agents, our distributions of agents over state variables will be noisy at approximating their continuous counterparts. Additionally, they will depend on the sequences of shocks that the agents receive. With a finite sample, the stochasticity of the draws will cause fluctuations in \MLvlest_t and \CLvlest_t. Therefore an informal way to measure the precision of our approximations is to examine the amplitude of these fluctuations.
First, some setup.
Simulate the economy for a sufficiently long “burn in” time .
Sample our aggregate estimates at regular intervals after . Letting the sampling times be , obtain \{\MLvlest_t\}_{t\in\mathcal{T}} and \{\CLvlest_t\}_{t\in\mathcal{T}}.
Compute the variance of approximation samples \text{Var}\left(\{\MLvlest_t\}_{t\in\mathcal{T}}\right) and \text{Var}\left(\{\CLvlest_t\}_{t\in\mathcal{T}}\right).
Other measures of uncertainty (like standard deviation) could also be computed
But variance is the natural choice because it is closely related to expected welfare
We will now perform exactly this exercise, examining the fluctuations in aggregates when they are approximated using the basic simulation strategy and Harmenberg’s permanent-income-neutral measure. Since each approximation can be made arbitrarily good by increasing the number of agents it uses, we will examine the variances of aggregates for various sample sizes.
# Setup computational environment:
# How long to run the economies without sampling? T_0
# Because we start the population at mBalLvl which turns out to be close
# to MBalLvl so we don't need a long burn in period
burn_in = 200
# Fixed intervals between sampling aggregates, Δt
sample_every = 1 # periods - increase this if worried about serial correlation
# How many times to sample the aggregates? n
n_sample = 200 # times; minimum
# Create a vector with all the times at which we'll sample
sample_periods_lvl = np.arange(
start=burn_in, stop=burn_in + sample_every * n_sample, step=sample_every, dtype=int
)
# Corresponding periods when object is first difference not level
sample_periods_dff = np.arange(
start=burn_in,
stop=burn_in + sample_every * n_sample - 1, # 1 fewer diff
step=sample_every,
dtype=int,
)
# Maximum number of agents that we will use for our approximations
max_agents = 100000
# Minimum number of agents for comparing methods in plots
min_agents = 100# Define tool to calculate summary statistics:
# Now create a function that takes HARK's simulation output
# and computes all the summary statistics we need
def sumstats(sims, sample_periods):
# sims will be an array in the shape of [economy].history elements
# Columns are different agents and rows are different times.
# Subset the times at which we'll sample and transpose.
samples_lvl = pd.DataFrame(sims[sample_periods,].T)
# Get averages over agents. This will tell us what our
# aggregate estimate would be if we had each possible sim size
avgs_lvl = samples_lvl.expanding(1).mean()
# Now get the mean and standard deviations across time with
# every number of agents
mean_lvl = avgs_lvl.mean(axis=1)
vars_lvl = avgs_lvl.std(axis=1) ** 2
# Also return the full sample on the last simulation period
return {
"mean_lvl": mean_lvl,
"vars_lvl": vars_lvl,
"dist_last": sims[-1,],
}We now configure and solve a buffer-stock agent with a default parametrization.
# Create and solve agent
popn = IndShockConsumerType(**init_idiosyncratic_shocks)
# Modify default parameters
popn.T_sim = max(sample_periods_lvl) + 1
popn.AgentCount = max_agents
popn.track_vars = ["mNrm", "cNrm", "pLvl"]
popn.LivPrb = [1.0]
popn.cycles = 0
# Solve (but do not yet simulate)
popn.solve()Under the basic simulation strategy, we have to de-normalize market resources and consumption multiplying them by permanent income. Only then we construct our statistics of interest.
Note that our time-sampling strategy requires that, after enough time has passed, the economy settles on a stable distribution of its agents across states. How can we know this will be the case? Szeidl (2013) and Harmenberg (2021) provide conditions that can give us some reassurance.
Szeidl (2013) shows that if
Undefined control sequence: \Rfree at position 19: …g \left[\frac{(\̲R̲f̲r̲e̲e̲\beta)^{1/\rho}… \log \left[\frac{(\Rfree\beta)^{1/\rho}}{\PermGroFac} \right] < \Ex[\log \PermShk],then there is a stable invariant distribution of normalized market resources \mNrm.
Harmenberg (2021) repurposes the Szeidl proof to argue that if the same condition is satisfied when the expectation is taken with respect to the permanent-income-neutral measure (\pShkNeutDstn), then there is a stable invariant permanent-income-weighted distribution (\mWgtDstnMarg)
We now check both conditions with our parametrization.
popn.check_conditions()
GPFacRaw = popn.bilt["GPFacRaw"]
e_log_PermShk_popn = calc_expectation(popn.PermShkDstn[0], func=lambda x: np.log(x))
e_log_PermShk_ntrl = calc_expectation(
popn.PermShkDstn[0], func=lambda x: x * np.log(x)
)
szeidl_cond = np.log(GPFacRaw) < e_log_PermShk_popn
harmen_cond = np.log(GPFacRaw) < e_log_PermShk_ntrl
if szeidl_cond:
print(
"Szeidl's condition is satisfied, there is a stable invariant distribution of normalized market resources"
)
else:
print("Warning: Szeidl's condition is not satisfied")
if harmen_cond:
print(
"Harmenberg's condition is satisfied, there is a stable invariant permanent-income-weighted distribution"
)
else:
print("Warning: Harmenberg's condition is not satisfied")Szeidl's condition is satisfied, there is a stable invariant distribution of normalized market resources
Harmenberg's condition is satisfied, there is a stable invariant permanent-income-weighted distribution
Knowing that the conditions are satisfied, we are ready to perform our experiments.
First, we simulate using the traditional approach.
# Find the stable market resources ratio (in expectation)
popn.calc_stable_points()
mNrmStE = popn.bilt["mNrmStE"]
# Set all agents to be "born" with the corresponding level of capital
Reff = popn.Rfree[0] / popn.PermGroFac[0]
popn.kLogInitMean = np.log((mNrmStE - 1)/Reff)
popn.kLogInitStd = 0.0
popn.update("kNrmInitDstn")
popn.initialize_sim()
popn.simulate()
# Retrieve history
mNrm_popn = popn.history["mNrm"]
mLvl_popn = popn.history["mNrm"] * popn.history["pLvl"]
cLvl_popn = popn.history["cNrm"] * popn.history["pLvl"]Update and simulate using Harmenberg’s strategy. This time, not multiplying by permanent income.
# Harmenberg permanent income neutral simulation
# Start by duplicating the previous setup
ntrl = deepcopy(popn)
# Recompute income process to use neutral measure
ntrl.neutral_measure = True
ntrl.update_income_process()
ntrl.initialize_sim()
ntrl.simulate()
# Retrieve history
cLvl_ntrl = ntrl.history["cNrm"]
mLvl_ntrl = ntrl.history["mNrm"]Now Compare the Variances of Simulated Outcomes¶
Harmenberg (2021) and Szeidl (2013) prove that with an infinite population size, models of this kind will have constant and identical growth rates of aggregate consumption, market resources, and noncapital income.
A method of comparing the efficiency of the two methods is therefore to calculate the variance of the simulated aggregate variables, and see how many agents must be simulated using each of them in order to achieve a given variance. (An infinite number of agents would be required to achieve zero variance).
The plots below show the (logs of) the estimated variances for the two methods as a function of the (logs of) the number of agents.
# Plots
# Construct aggregate levels and growth rates
# Cumulate levels and divide by number of agents to get average
CAvg_popn = np.cumsum(cLvl_popn, axis=1) / np.arange(1, max_agents + 1)
CAvg_ntrl = np.cumsum(cLvl_ntrl, axis=1) / np.arange(1, max_agents + 1)
MAvg_popn = np.cumsum(mLvl_popn, axis=1) / np.arange(1, max_agents + 1)
MAvg_ntrl = np.cumsum(mLvl_ntrl, axis=1) / np.arange(1, max_agents + 1)
# First difference the logs to get aggregate growth rates
CGro_popn = np.diff(np.log(CAvg_popn).T).T
CGro_ntrl = np.diff(np.log(CAvg_ntrl).T).T
MGro_popn = np.diff(np.log(MAvg_popn).T).T
MGro_ntrl = np.diff(np.log(MAvg_ntrl).T).T
# Calculate statistics for them
CGro_popn_stats = sumstats(CGro_popn, sample_periods_dff)
CGro_ntrl_stats = sumstats(CGro_ntrl, sample_periods_dff)
MGro_popn_stats = sumstats(MGro_popn, sample_periods_dff)
MGro_ntrl_stats = sumstats(MGro_ntrl, sample_periods_dff)
# Count the agents
nagents = np.arange(1, max_agents + 1, 1)
# Plot
fig, axs = plt.subplots(2, figsize=(10, 7), constrained_layout=True)
fig.suptitle("Variances of Aggregate Growth Rates", fontsize=16)
axs[0].plot(
nagents[min_agents:],
np.array(CGro_popn_stats["vars_lvl"])[min_agents:],
label="Base",
)
axs[0].plot(
nagents[min_agents:],
np.array(CGro_ntrl_stats["vars_lvl"])[min_agents:],
label="Perm. Inc. Neutral",
)
axs[0].set_yscale("log")
axs[0].set_xscale("log")
axs[0].set_title("Consumption", fontsize=14)
axs[0].set_ylabel(
r"$\Delta \log \left(\{\hat{C}_t\}_{t\in\mathcal{T}}\right)$", fontsize=14
)
axs[0].set_xlabel("Number of Agents", fontsize=10)
axs[0].grid()
axs[0].legend(fontsize=12)
axs[1].plot(
nagents[min_agents:],
np.array(MGro_popn_stats["vars_lvl"])[min_agents:],
label="Base",
)
axs[1].plot(
nagents[min_agents:],
np.array(MGro_ntrl_stats["vars_lvl"])[min_agents:],
label="Perm. Inc. Neutral",
)
axs[1].set_yscale("log")
axs[1].set_xscale("log")
axs[1].set_title("Market Resources", fontsize=14)
axs[1].set_ylabel(
r"$\Delta \log \left(\{\hat{M}_t\}_{t\in\mathcal{T}}\right)$", fontsize=14
)
axs[1].set_xlabel("Number of Agents", fontsize=10)
axs[1].grid()
axs[1].legend(fontsize=12)
plt.show()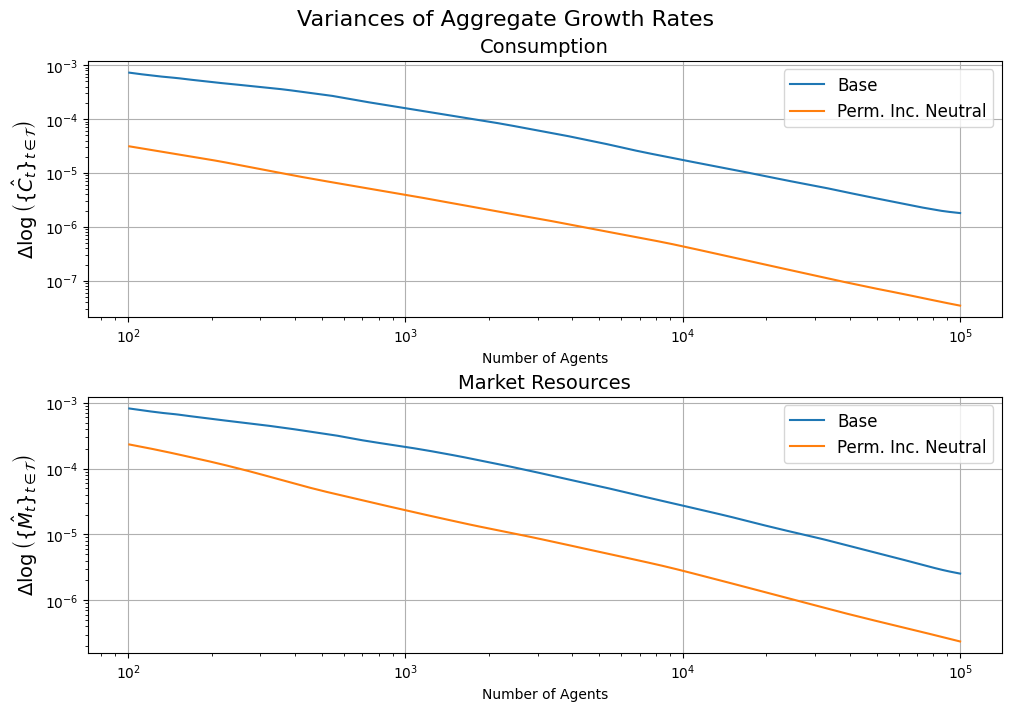
Harmenberg’s Method Produces Large Gains in Efficiency¶
The number of agents required to achieve a given variance is revealed by choosing that variance and then finding the points on the horizontal axis that correspond to the two methods.
The upper variance plot shows that the efficiency gains are very large for consumption: The horizontal gap between the two loci is generally more than two orders of magnitude. That is, Harmenberg’s method requires less than one-hundredth as many agents as the standard method would require for a given precision. Alternatively, for a given number of agents it is typically more than 10 times as precise.
The improvement in variance is smaller for market resources, likely because in a buffer stock model the point of consumers’ actions is to use assets to absorb shocks. But even for \MLvl, the Harmenberg method attains any given level of precision (\text{var}\left(\{\MLvlest_t\}_{t\in\mathcal{T}}\right)) with roughly one tenth of the agents needed by the standard method to achieve that same level.
Of course, these results apply only to the particular configuration of parameter values that is the default in the HARK toolkit (but which were chosen long before Harmenberg developed his method). The degree of improvement will vary depending on the calibration -- for example, if the magnitude of permanent shocks is small or zero, the method will yield little or no improvement.
# Execute the line below to see that there's little drift from mNrmStE as starting point
# (after setting burn_in to zero above). This means burn_in does not need to be large:
plt.plot(np.arange(1,len(np.mean(MAvg_ntrl,axis=1))+1),np.mean(MAvg_ntrl,axis=1).T)
plt.show()
- Harmenberg, K. (2021). Aggregating heterogeneous-agent models with permanent income shocks. Journal of Economic Dynamics and Control, 129, 104185. 10.1016/j.jedc.2021.104185